

As part of my consulting work, I collect a lot of broadcast TV streams. A lot of them. At present there’s about 70 terabytes worth representing more than 400 days (that’s right, more than 9600 hours) of broadcast TV. Storing all that data’s not straightforward, since I want to ensure that it doesn’t get lost or damaged.
So the data is partitioned among four servers, each with six hard drives. Within each server, Linux software RAID-5 is used so that in the event that a hard drive fails (or the cable, or the controller), then the data can be recovered by swapping out that drive and letting the RAID reconstruct itself. In turn, each of these servers is duplicated, for a total of eight servers and 48 hard drives dedicated to storing these streams.
To ensure everything is working properly, the RAIDs rebuild themselves every month or so (verifying that all the hardware is up to snuff). In addition a full data comparison of the primary and duplicate servers is performed. Just to be safe.
So with RAID-5 within each server, and full redundancy, and periodic verification, one would think my precious streams would be well-guarded. Imagine my surprise when on a recent full data compare, some of the files didn’t match up.
Ok, so maybe I wasn’t that surprised. RAID-5 allows you to recover if a hardware failure results in a loss of one hard drive. However it does nothing to protect the integrity of the data. Should there be a glitch while the bits are crossing a wire, or being stored on the hard drive, or even while stored in memory, you’re out of luck. (To some extent CRCs and other mechanisms that are built into storage protocols and devices do protect you, so while RAID-5 itself doesn’t get you any integrity it’s not as if you’re wholly unprotected from having your bits forget who they are. Regrettably while these mechanisms can let you know that your data has undergone a personality change, it may not be able to tell you what it originally was.)
On analyzing the files that compared differently, one bit had flipped. In one case the, the file on the primary server had a 0x3A byte and the duplicate server had a 0x3E byte.
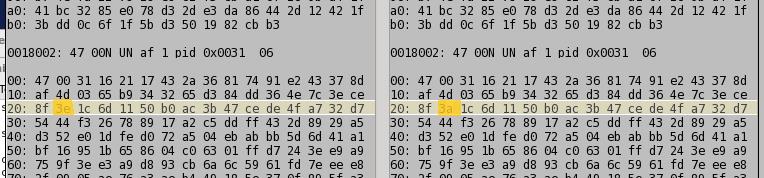
A one bit difference. How did this bit flip? I’m not entirely sure. In theory rsync would verify that when the files were first duplicated, they were identical. It does this by verifying the checksum of the original and new file (and these checksums are now different). Moreover these files compared fine a few months ago. So it would appear that the bit had flipped on the hard drive platters themselves.
So on one of my servers, six files are corrupt – one bit has been flipped in each. Which one is correct? Alas, at present I have no way to determine this. Because the error is so subtle – just one bit – the corrupted data is still a legal video stream. Had more data been in error, it’s likely that certain counters or other checkpoints in the stream would have been damaged, and it would have been clearer which one was damaged.
What is really needed is a checksum for the data that is managed by the filesystem. Traditionally this is not provided by the Linux ext2/3/4 filesystems (I use ext4). BTRFS does (and in general has a goal of detecting the type of bit rot I’m talking about here), and I’ll in all likelihood use it in the next server, just to see if its a viable option.
In the interim, I’ve generated checksums for each file on each server so that the next time the bits go out to party, I’ll be able to determine who had a bit too much to drink.