

A lot of effort goes into making sure that the episode of America’s Funniest Home Videos you watched last night was as pristine as possible. From the network’s broadcast center to your local TV station’s transmission tower to that antenna on your roof, and finally to your DVR, a number of mechanisms ensure that all those 1s and 0s in the digital broadcast get to you unscrambled and in the right order.
But from time to time lightning storms, swaying trees, and stray cats will wreak havoc on the signal. Filters, error detection and correction codes, and even the most elaborate incantations of RF engineers struggle to make sense of the distorted waveform being received. Inevitably the occasional glitch sneaks past and you end up recording some damaged audio and video. The last bastion of defense for couch potatoes lies in the MPEG decoder and player’s ability to try to make some sense of the damaged programming. In many cases some sleight of hand can mitigate the visual effect of the damage, and occasionally the errors can be concealed so well that they’re invisible to the casual viewer.
We’re going to focus in this article on error concealment of MPEG-2 video. But the general principles apply to other video compression schemes such as H.264 and H.265.
Not All Packets are Created Equally
In the San Francisco Bay Area we had a prime example of how varied the visual effect of losing a single transport packet can be. In the Spring of 2017, a local broadcaster had a problem where a single transport packet was dropped every 180 ms or so. With that frequency there were a lot of damaged pictures. Yet, the most observable artifacts were stripes in the video every couple seconds. These were certainly annoying, but they wouldn’t stop you from watching your program. The picture would also periodically break up completely, but the vast majority of the errors were going by unnoticed.
Part of the reason that a particular dropped or damaged packet may not result in observable artifacts is simply because it may not be part of the program you’re watching. Most ATSC transport streams carry multiple programs. For example, the local ABC affiliate’s broadcast contains three programs: the main ABC feed in 720p at 7-1, LiveWell Network in 720p at 7-2, and Laff TV in 480i at 7-3. If we’re watching ABC’s programming we really don’t care if a LiveWell or Laff packet gets corrupted. If we look at the distribution of packets in the transport stream, roughly 47% of the packets are for ABC 7-1, 41% for LiveWell 7-2, and 9% for Laff 7-3. So if we’re watching Once Upon a Time on ABC we only care about the health of 47% of the total packets.
In the Spring of 2017 problem, only single transport packets were being dropped. In well-received channels it’s not uncommon for one or two packets of a program to be lost or in error from time to time. It’s also not uncommon for there to be periods where a few dozen packets may be in error. Whether those errors result in visibly corrupted pictures is what we’ll be looking at in the remainder of this post. There are of course also cases where hundreds of packets may be in error. In principal the same error concealment strategies apply whether a few or a few hundred packets are damaged.
MPEG-2 Video GOP Structure
Before we talk about how a decoder or player can react to damaged compressed video, we need to understand a bit more about how MPEG-2 video is compressed. In particular we need to understand how errors in one picture can propagate across multiple pictures. Those of you already familiar with MPEG-2 video GOP sequences may want to jump ahead.
ATSC 1.0 uses the MPEG-2 video compression scheme, which utilizes three types of pictures: I, P, and B. The figure below illustrates the relationship between the three picture types. The sequence of pictures starting with an I-picture (and usually followed by some number of P and B pictures) is called a group of pictures, or GOP.
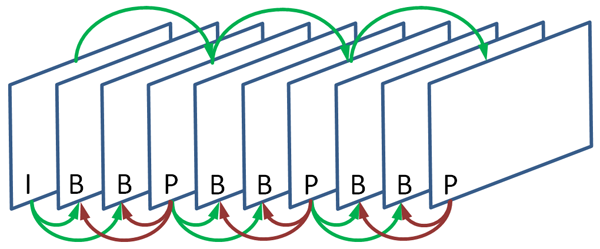
- I-pictures are (I)ndependently coded. All of the information required to decode an I-picture is contained within the I-picture’s compressed data. They are similar to JPEGs or PNGs or other compressed still images.
- P-pictures are (P)redicted from a reference picture – a previously decoded I- or P-picture. The idea here is that there tends to be a lot of similarity among pictures that are close together in time. So wouldn’t it be great to only encode the difference?
P-pictures reduce the amount of information they need to encode by exploiting their similarity to a previous picture. The previous picture used is called a reference picture. Imagine a scene where a ball flies across the screen with a static background. From frame to frame the background is more or less identical, so there’s no value in encoding it over and over again. When it comes time to encode parts of the picture that include the background, the encoder will look in the reference picture for something similar. Since the background is static, it’ll find a rather good match in exactly the same spot in the reference picture. Then it’ll only encode what subtle differences remain, for example the difference caused by slow moving clouds or swaying trees.
The ball of course will be moving, but if you ignore that motion the ball also probably looks more or less the same frame to frame. It’s just its position in the frame that’s changing a lot. So when it comes time to encode the part of the picture containing the ball, the encoder will (eventually) find the ball in the reference picture and use that as a basis. The P-picture will encode any subtle differences in the ball’s appearance (resulting, for example, from differences in rotation or size).
In order to decode a P-picture, you need both the compressed data for the P-picture as well as the decoded reference picture. - B-pictures are (B)idirectionally predicted. While P-pictures predict from a prior picture, B-pictures predict from a prior and a future reference picture. A particular part of the B -picture can predict from the prior picture, the future picture, or a blend of the two. Because there are so many opportunities to find similarities, B-pictures tend to be the most compact of all the picture types. However, B-pictures never serve as reference pictures in MPEG-2 video.
(Some of you may wonder how a B picture can predict from a future reference picture. How can a future reference picture be available? No, the MPEG-2 standard doesn’t include the specifications for time travel. Instead, it specifies that compressed pictures are transmitted out of order. They’re transmitted in the order in which they need to be decoded, which is different from the order in which they need to be displayed. So the future reference picture is in the future from a display standpoint, but not from a decoding standpoint.)
The IBBPBBP… sequence depicted above is a classic GOP sequence, but variations may occur in ATSC broadcasts. In fact the current generation of encoders tend to dynamically optimize the pattern by analyzing the video as it is encoded. As a result, some GOPs may be longer than others, and there may be more or less than 2 B-pictures between reference pictures.
Error Propagation in GOPs
Now that we know about the various picture types and how they rely on each other, we can begin to understand how damage to the compressed video affects what ends up on the screen. If an I-picture is damaged, then that damage can propagate to the P-picture which predicted from it. It can also propagate to the P-picture that predicted from that P-picture, and so-on. And it may propagate to the B-pictures which predicted from the I- and indirectly through the P-pictures. So a hit to an I-picture can affect the display of every picture in the GOP.
Note that we say that the damage may propagate to B- and P-pictures. It will if the B- and P-pictures rely on the damaged area. If the B- and P-pictures don’t rely on the damaged area, then the damage of course won’t spread.
Now if a P-picture is damaged, things are similar to the I-picture – all following P-pictures which predicted from it may be damaged, and the same for B-pictures.

The diagram above illustrates what can happen if the P-picture in red is damaged. The pinkish frames are the frames which, either directly or indirectly, rely on that P-picture. In effect the damage can propagate until an I-picture starts a new GOP.
If a B-picture is damaged then we’re in some luck. B-pictures are the end of the road and noone predicts from them. So if a B-picture is damaged then it may be displayed incorrectly, but no other pictures will be affected.
Concealing Damaged Pictures
So we ‘ve got some damaged pictures. Early video decoders had a limited ability to handle errors in the MPEG video bitstream, and you’d end up seeing streaks or blocks. Depending on the frame rate and whether an I-, P-, or B-picture was hit, these artifacts could last anywhere from 1/60th of a second to a half second or longer.
‘ve got some damaged pictures. Early video decoders had a limited ability to handle errors in the MPEG video bitstream, and you’d end up seeing streaks or blocks. Depending on the frame rate and whether an I-, P-, or B-picture was hit, these artifacts could last anywhere from 1/60th of a second to a half second or longer.
Modern MPEG-2 video decoders have come a long way in being able to detect errors in the bitstream and take an appropriate action to mitigate its visual effect. Detection can occur at two levels. One level is at the transport stream level. Every transport packet contains a Transport Error Indicator (TEI) bit. If this bit is set, then the payload of the packet was damaged somewhere along the way. It may be just one bit, or it could be all 184 bytes of the payload that are in error. It is a hint to downstream components, such as the MPEG-2 video decoder. (On the broadcast side of things, ATSC 1.0 uses Reed-Solomon coding, which allows reception errors to be detected, and in some cases corrected. When correction isn’t possible the TEI bit gets set.)
In addition to the TEI bit, the MPEG-2 video decoder can look for illegal syntaxes or oddities in the MPEG-2 video bitstream. For example, it could detect illegal motion vectors. Going back to our example of encoding a ball flying across the screen, the ball in the P-picture is predicted from the ball in the I-picture. But the ball is in different positions, so the P-picture has to say where in the I-picture the ball is predicted from. That where is communicated via a motion vector. Now if the motion vector points outside of bounds of the I-picture, there’s almost certainly something wrong.
While detecting errors is somewhat straightforward, determining how to conceal errors requires some creativity.
A simple mechanism is to simply drop damaged pictures. The premise is that it’s better to see still video for a while rather than the horribly blocky mess that might otherwise be displayed. This works exceptionally well if you only need to drop one picture. In all likelihood no one will notice the missing picture. Even dropping two or free pictures tends be ok, though picture dropping is less effective if the damage propagates to a dozen or more frames.
More sophisticated mechanisms rely on analyzing the picture. For example, in the case of the ball moving across the screen, the decoder can note that the area of the picture containing the ball is damaged and try to fill it in. It could just copy pixels from the same area in the previous frame. Or it could notice the motion of the ball moving across the video, deduce that the damaged area contains the ball, and take the image of the ball from a nearby picture. (In reality encoders don’t do object recognition. At least not today. However they can detect patterns in motion vectors and use that information to make educated guesses on how regions of the picture are moving.)
Error Concealment in Action
One of the more interesting examples of error concealment – and player deficiency – I’ve encountered is shown below. When played with VLC 2.2.8, the error’d sequence lasts for nine frames, of which eight are shown below. Frame 1 is the error-free picture preceding the error’d frames. The video is from a 1080i program, so nine frames equates to roughly a third of a second.

However when the same MPEG-2 transport stream is played with the Windows 10 Movies & TV app, there is no evidence of any damage.

To gain some insight into what the Movies & TV app might be doing, let’s take a look at the exact nature of the damage.
The damaged picture is a B-picture in a group-of-pictures containing 27 pictures. It has the following pattern:
The damaged picture is the B-picture highlighted in red. The nature of the damage is that six of the transport packets have errors (the Transport Error Indicator bit is set), followed by some number of missing packets. The number of packets missing in the transport stream is 201, however its difficult to say how many of those packets are for the video stream in the program we’re looking at. Statistically it’s likely to be between 75 and 100 packets.
By looking deeper into the structure of the B-picture, we can see that the first 16 and last 13 slices appear to be intact. In most MPEG-2 coded video (and the case for this particular broadcast), a slice is a 16-pixel high stripe of the picture. Since this picture is 1080 pixels high, it has 68 slices. So a bit more than half of the middle of the picture is damaged or missing. We know that this is a result of damage since in MPEG-2 Main Profile (which is what is used for ATSC 1.0), every part of the picture needs to be part of a slice. (Note that the pictures in the sequences shown above, the top, bottom, and right of the pictures were cropped to highlight the incorrectly rendered areas.)
Having half of the picture missing is a non-trivial amount of damage so the decoder/player has its work cut out for it. The Movies & TV app does an admirable job of rendering the sequence, and there’s really no visual clue that there was an error. In reality, it appears that the player, at least in this instance, has simply dropped the damaged B-picture.
Because the re is so little motion, even blending regions from the previous and next frame gives rather good results. ffmpeg does frame blending for this particular error, as can be seen in the image to the right. The blending is rather obvious in areas containing motion, for example the arm and hand. While the blended areas stand out in the still picture, they aren’t noticeable when the video is played at normal speed.
re is so little motion, even blending regions from the previous and next frame gives rather good results. ffmpeg does frame blending for this particular error, as can be seen in the image to the right. The blending is rather obvious in areas containing motion, for example the arm and hand. While the blended areas stand out in the still picture, they aren’t noticeable when the video is played at normal speed.
But what about the following frames that aren’t displayed properly by VLC? Those of you who’ve been paying attention are probably saying, “But errors from a B-picture shouldn’t propagate!” And you’re entirely right. In MPEG-2 video, no pictures use B-pictures as a reference. Only I- and P-pictures can serve as reference pictures.
It’s not really clear why VLC 2.2.8’s playback is so adversely affected. This was observed both on the VLC for Windows and VLC running on a CentOS 7 system. It could be a bug in the player triggered by an illegal syntax in the bitstream, or it may be that VLC has an exceptionally tough time recovering from damaged bitstreams. The MPEG specification specifies how correctly formed bitstreams are decoded. It doesn’t specify how a decoder or player should behave in the presence of malformed bitstreams. (For that matter the specification also doesn’t say anything about how to encode video…just what a conforming output of an encoder looks like.) Fortunately this deficiency has been corrected in VLC 3.0.1.
Enjoyed reading this technical insight. Just ran across your page(s) as I’m having trouble with a couple Homerun HD’s (Quattro and Extend).. Just trying to understand why they are doing what they are doing. Thanks!